SCORM Quiz – Item Analysis issues & solution
SCORM is widely used in the eLearning community so I will not get into what it is, rather I will get straight into the fundamental issue it presents for a Learning Management System (LMS) from Quiz reporting perspective. This is based on my first hand experience while developing EduBrite LMS and having seen a variety of SCORM content thru several customers.
Most LMSs (including EduBrite) have some kind of built in Quiz creation feature. (We are focusing the discussion only on LMSs that provide quiz-authoring capabilities). As a eLearning content developer you have option to use the built in Quiz feature or embed the Quiz questions inside a SCORM package that you can create using authoring tools (like Storyline or Captivate). You can even hand code a SCORM if you are taking deep dive into 700+ pages specification and have reasonable experience with Javascript.
In this article I will discuss the implications of your choice, from the reporting perspective between SCORM based quizzes vs natively created quiz in LMS. This will also help in setting the right reporting expectation from LMS, an eLearning developer can have.
Generally, for the Quizzes created in LMS, we have seen far superior and usable reporting but for SCORM based quizzes, the reporting doesn’t go that far or isn’t that usable especially from the non-technical user’s perspective. And it often leads to dissatisfaction among the LMS customers, because they expect LMS to provide same usable reports, regardless of whether they are using SCORM or using built in quiz in LMS.
At EduBrite we created a mechanism based on data mining to provide same reporting for SCORM quizzes as what is available for quizzes directly built in LMS. But this feature is experimental and isn’t full proof yet to cover all scenarios, especially considering wide variety of authoring tools and few areas where SCORM specification leaves things open to implementations.
In this article I will first describe technical challenge in reporting for SCORM based quizzes, and that would explain the differences and limitation you will find when you use then in any LMS. I will also explain how EduBrite tried to solve it (although not with full perfection), and (few) shortcomings in our solution.
To set the context for remainder of this article, lets look at an example of a very commonly seen multiple-choice quiz question.
Question
What is 10+2
- 10
- 11
- 12
- 13
Design time
First let’s look at the design time (authoring time) difference from the data awareness point, and by design time, I mean until this question is attempted by a user. When you create the quiz/question in LMS, it knows everything about it, like question id (internally assigned by LMS), question type, question statement, choices, correct answer. But when you create the same question in SCORM, and upload the package (zip) in LMS, LMS knows nothing about this question. What you packaged inside the SCORM zip file is completely opaque to the LMS, except for the manifest, which only describes SCO you have inside the package.
Runtime
Let’s look at what data points LMS can get in both cases, when a student attempts the question.
A. LMS Quiz
When you use built in authoring of LMS, it is able to capture student’s answers to this question and link it to the already known question id in the LMS.
Consider that student picked up a correct answer 12 (3rd choice). LMS would immediately know that out of the four available choices, user has picked 3rd choice which was correct, when was the question attempted, how much time the user spent on the question and what should be the score for this attempt.
If the above question is attempted multiple times, by multiple students, LMS can provide an Item Analysis report about difficulty level of the question, e.g.
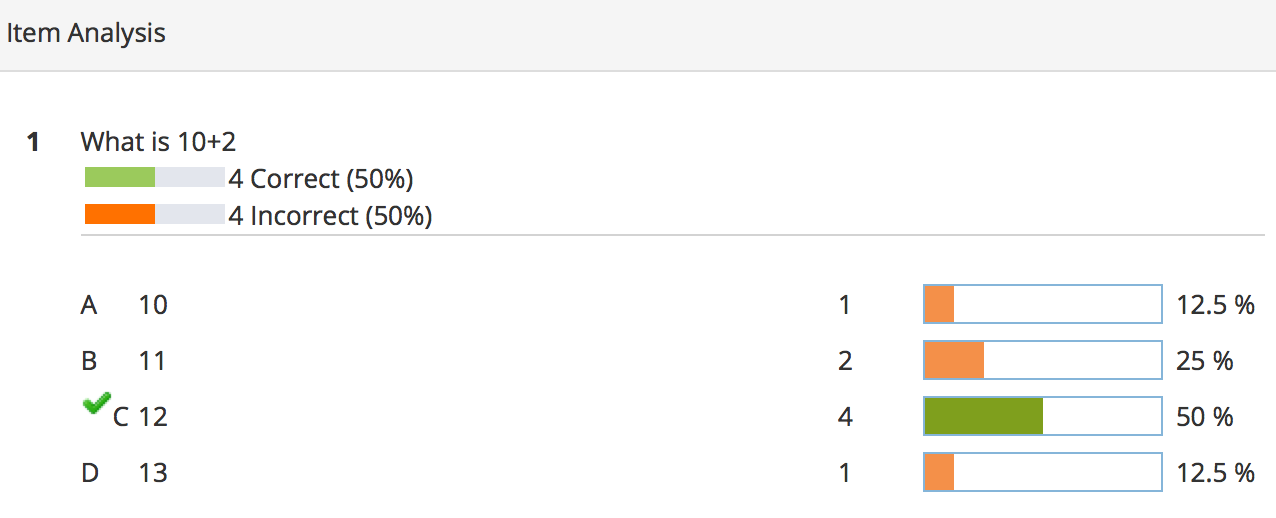
LMS can also provide a report to show student’s attempt and full context of the answers they selected.
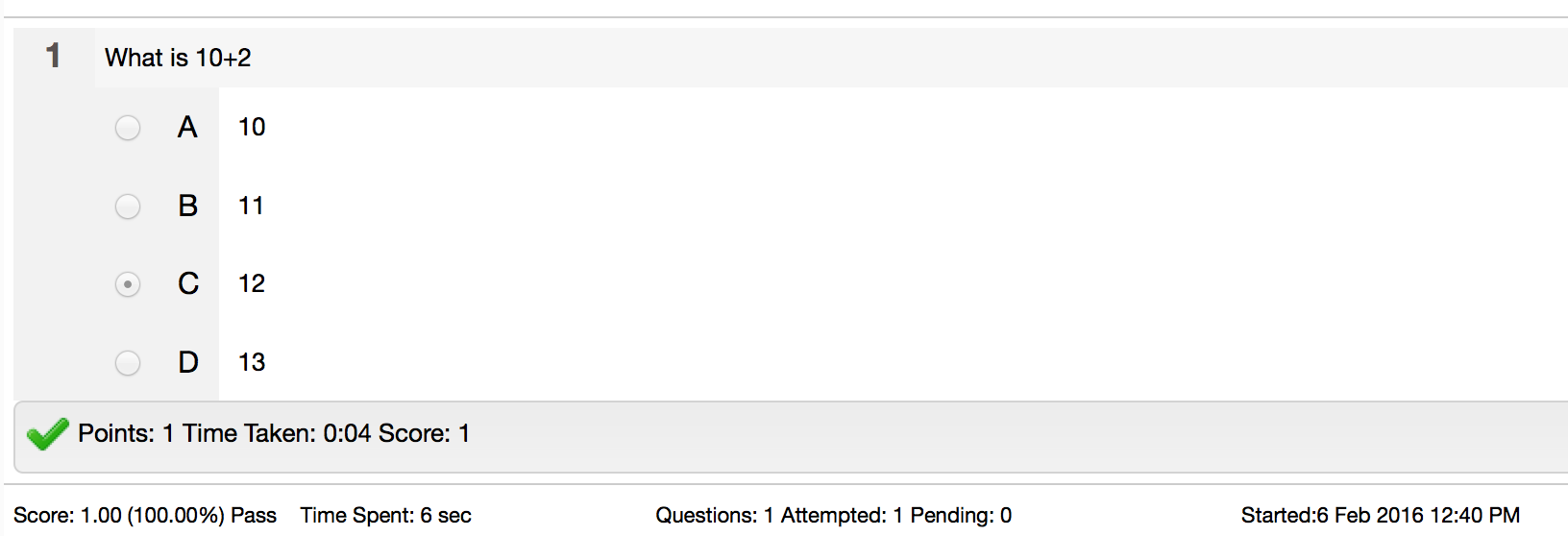
B. SCORM Quiz
Now if we were using SCORM, lets see how the situation changes. When student submits the response to the question, SCORM will send a set of data elements known as interactions in specification. For example SCORM might send something like this to the LMS –
cmi.interactions.0.id – Q1
cmi.interactions.0.type - choice
cmi.interactions.n.learner_response - 12
cmi.interactions.n.correct_responses._count - 1
cmi.interactions.n.correct_responses.0.pattern - 12
cmi.interactions.n.result – correct (we have seen variations like correct/incorrect or 1/0 in content produced in different authoring tools)
cmi.interactions.n.weighting – 1 (commonly interpreted as score or relative score w.r.t. total score)
cmi.interactions.n.timestamp – 114-01-04T21:23:37 (interaction time)
cmi.interactions.2.latency - PT00H00M02S (time spent on this interaction)
So upon receiving this data set, LMS becomes aware of this question for the first time in its lifecycle. It knows the question ID, the type of question, what was student’s response, what is the correct response, whether the student’s response was correct or incorrect, score, time of the attempt and time spent on the attempt.
Important things that LMS doesn’t know yet, which was available when question was built in LMS are –
- What exactly was the question (statement)?
- How many choices were there in the question, or what other choices were available to pick from, that may be correct or incorrect
We can address first of the above two points by using SCORM 2004 (if LMS also supports it). In SCORM 2004, new data element “description” was introduced for interactions. You can send following new element about the interaction to the LMS.
cmi.interactions.0.description = What is 10+2
With this new element, LMS can report what was the question, and what was student’s answer, and whether it was correct or incorrect. But it still doesn’t know about the other available choices (other three that are incorrect but are not picked by the student).
Solution
As a LMS provider, here is how we tried to tackle this issue, and provide full report similar to questions created in LMS.
If large number of students attempts the above question in SCORM over a sufficiently long period, statistically at some point some student will pick each available choice (probability 1/4). And if LMS could correlate several interactions record to correspond to same question ID, it can learn about all other incorrect choices, or keep learning more possible incorrect choices with time.
E.g. when a student picks the first (incorrect) choice, LMS will see following data elements:
cmi.interactions.0.id – Q1
cmi.interactions.n.learner_response – 10
cmi.interactions.n.result – incorrect
cmi.interactions.n.weighting – 0
And assuming LMS has seen question id Q1 before, it can check whether it has also seen the answer 10 before or not. If not, it can add 10, to the other available choice for the same question. And it also knows that this is the incorrect answer.
Similarly when LMS sees another incorrect answer
cmi.interactions.n.learner_response – 11
it would learn that there is another incorrect option available for the same question. Eventually LMS will learn about the fourth (all) option when it sees
cmi.interactions.n.learner_response – 13
By correlating all the above interactions to same question, it can fully re-engineer how the question looks like. And now, it can provide same kind of report, as the quiz created natively in LMS. It can also show the question context when showing details of a student’s attempt.
But in order to accomplish this correlation, LMS should be able to unambiguously match question ids among several interactions (from several students) that are reported to it. The first thing that is needed is to only consider the interactions reported by the same SCORM package. And this is where the ID of the SCORM package as mentioned in the manifest can be used, along with the internal id that LMS may have assigned to the uploaded SCORM.
So it appears that we do have a solution that can give same (full) reports for the quiz question (interactions) embedded within SCORM. Nice. But there are few cases where we need to be cautious.
1. Multiple Attempts (interactions)
Multiple interactions on the same question (or re-attempts) provide an interesting case. We noticed that different authoring tools (or elearning developers) have different ways to represent the interactions ids.
Some re-use the same question id (effectively overwriting the previously stored answer) following a technique referred as Sate, while some other tools add an attempt count suffix to the question id, for each unique interaction. E.g. Q1_1, Q1_2 etc, referred as Journaling. (ref – Tim Martin http://scorm.com/blog/2010/11/4-things-every-scorm-test-should-do-when-reporting-interactions/). Although we found inconsistencies among tools in how they generate Ids even when using Journaling to not overwrite answers from previous attempts.
This presents a potential problem while reverse engineering; because LMS can’t cleanly (or consistently) correlate these interactions to the same question ID and might interpret each attempt of the same question as a new question. This effectively limits the accuracy of the item analysis because same question may be reported (or interpreted) as different question depending on the attempt (first attempt, second attempt).
Based on our analysis of several packages from several authoring tools (like created in Storyline, Captivate and few others), we have devised a pattern-based logic to derive the question id and attempt numbers accurately. But this may not be fully accurate in handling all authoring tools and ID naming conventions.
2. SCORM ID in Manifest
If content developer changes the SCORM content (questions and/or choices) but keeps the same ID in the manifest and replaces it for the existing uploaded package in LMS, the reporting can completely go out of sync. Because LMS would incorrectly correlate unrelated questions because they will be assumed to be part of same SCORM due to same ID in the manifest. This can be avoided easily by using new ID in the manifest (unless the changes are minor).
3. Randomization
If the SCORM has internal logic to randomize the questions, but it doesn’t sends the consistent interaction IDs regardless of the position (sequence), then the reporting becomes inconsistent. eLarning developers can also solve this by using IDs in consistent manner.
4. Multiple correct answers
We have noticed inconsistent behavior in how SCORM tools report the correct_responses and learner_response. Some tools embed choice identifier (like a, b, c etc) in the response, while others don’t. Similarly when there are multiple answers some use comma delimited while others use space, tab or other conventions. This is one of the open problems we are working on and based on known conventions of many tools we can solve it to some extent.
5. Probability
We assume that statistically all choices will be picked up at least ones, but practically there is no finite time-frame in which it will happen. So when you are looking at reports, you might find an incomplete list of choices for a question in LMS.
All the above problems can be avoided during SCORM content development, by having a little more closer attention to the IDs and having a perspective that what runtime data SCORM sends to LMS can be used for further correlation and analysis.